
I'm going!
Let’s try a Saturday afternoon!
From 1-3pm, join us for an IndieWeb Meetup at Think Coffee on 8th Av at 14th St in Manhattan!
Come work on your personal website, whether it exists yet or not!
This post from Calum finally brought out the FOMO I had been suppressing for IndieWebCamp Berlin.
Really looking forward to the 2019 IndieWeb Summit June 29-30th in Portland!

There was something else I wanted to mention in my post the other day, but left it out because it was getting a bit long. The first screenshot contains the unexplained piece of text: "To follow indieweb add a reader" followed by a settings link. (Here it is again...)
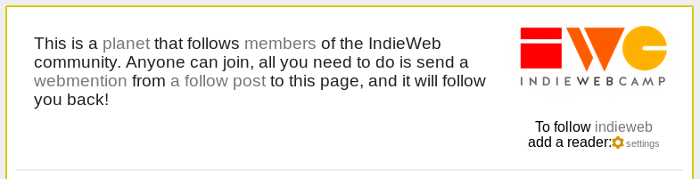
I added this because it's an easy way to add a rel=feed to the page. It's a separate module in Dobrado that allows setting some values for the account. One of the options allows specifying what feeds you want to make discoverable, so in this case I have it set to indieweb/directory which is the microformats feed list for all the feeds shown on that page.
The module renders that link, marked up with rel=feed, along with the logo and account name as an h-card for the account. The other thing it does is provide a webaction, which is why rather than just being a link it mentions adding a reader. Clicking the settings link opens a dialog that lets you specify your web action config. If the dialog finds a valid config it will trigger an update to any indie-action tags it finds on the page. There just happens to be one in the module I've just mentioned, so it will now looks like this:
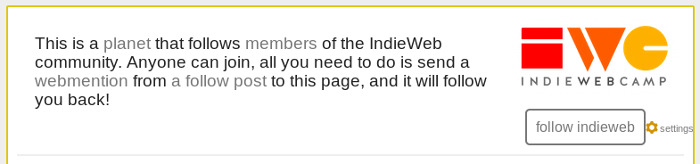
The link "follow indieweb" is now using my config! It's pointing at my own reader with a follow action set, so if I click on that link all I have to do is click ok in my reader to add the feed. As it turns out I'm already following the indieweb directory on unicyclic.com, and my webaction config has checked this too!
One of the options set in my config is status and it happens to work a little differently from the other actions. This config option supports CORS requests, and will provide information about urls when I'm logged in. The request is made during the config check mentioned above, so the page actually looks like this for me:
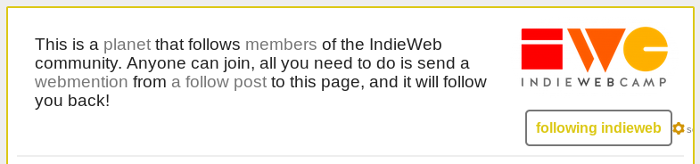
The status endpoint supports multiple urls at a time, so it gets called for all indie-action tags on a page, and returns information for other actions too such as likes, replies and reposts. When it finds an action set for a url, that action will also be highlighted on the page.
I added this because it's an easy way to add a rel=feed to the page. It's a separate module in Dobrado that allows setting some values for the account. One of the options allows specifying what feeds you want to make discoverable, so in this case I have it set to indieweb/directory which is the microformats feed list for all the feeds shown on that page.
The module renders that link, marked up with rel=feed, along with the logo and account name as an h-card for the account. The other thing it does is provide a webaction, which is why rather than just being a link it mentions adding a reader. Clicking the settings link opens a dialog that lets you specify your web action config. If the dialog finds a valid config it will trigger an update to any indie-action tags it finds on the page. There just happens to be one in the module I've just mentioned, so it will now looks like this:
The link "follow indieweb" is now using my config! It's pointing at my own reader with a follow action set, so if I click on that link all I have to do is click ok in my reader to add the feed. As it turns out I'm already following the indieweb directory on unicyclic.com, and my webaction config has checked this too!
One of the options set in my config is status and it happens to work a little differently from the other actions. This config option supports CORS requests, and will provide information about urls when I'm logged in. The request is made during the config check mentioned above, so the page actually looks like this for me:
The status endpoint supports multiple urls at a time, so it gets called for all indie-action tags on a page, and returns information for other actions too such as likes, replies and reposts. When it finds an action set for a url, that action will also be highlighted on the page.

My #CSS tip for tonight: Learn & try out CSS Custom Properties (AKA #CSSVariables)!
Simple examples on MDN:
* https://developer.mozilla.org/en-US/docs/Web/CSS/var
Used them to implement theming on my site @IndieWebCamp Berlin, felt like they made my CSS more maintainable too!
Simple examples on MDN:
* https://developer.mozilla.org/en-US/docs/Web/CSS/var
Used them to implement theming on my site @IndieWebCamp Berlin, felt like they made my CSS more maintainable too!
Prioritizing simple & maintainable is perhaps most in contrast to enterprise systems, or any system that requires a separate IT person. Minimum viable ops.
#indieweb features & systems should be as easy (easier!) to setup & maintain than smartphones (which have sadly regressed in simplicity & maintainability over the years).
#indieweb features & systems should be as easy (easier!) to setup & maintain than smartphones (which have sadly regressed in simplicity & maintainability over the years).
@doriantaylor sounds like a good minimization of tech dependencies, I think we align on principles there.
I have found XSLT hard to “come back to”, e.g. maintaining @H2VX, compared to PHP. #microformats2 is a good alternative to RDFa. v2 syntax has vocabulary independence (and a well defined and tested parsing specification) with the ability to create & use your own custom terms, but simpler, prefixing like HTML5’s "data-*" attributes without worrying about explicit URL based namespaces and fragile qnames.
We can likely do even better. Good to see multiple approaches to the principles of simpler setup & maintenance, plenty of learning opportunities I’m sure.
I have found XSLT hard to “come back to”, e.g. maintaining @H2VX, compared to PHP. #microformats2 is a good alternative to RDFa. v2 syntax has vocabulary independence (and a well defined and tested parsing specification) with the ability to create & use your own custom terms, but simpler, prefixing like HTML5’s "data-*" attributes without worrying about explicit URL based namespaces and fragile qnames.
We can likely do even better. Good to see multiple approaches to the principles of simpler setup & maintenance, plenty of learning opportunities I’m sure.
Under the hood I wanted theming that is simple & maintainble. Perhaps implicit #indieweb pragmatic design principles, since we are creating features & systems that individuals can understand & maintain, likely those with less time (e.g. future selves).


During #IndieWebCamp #Berlin I built a simple theme switcher for my site!
hyperlinks -> URL query param -> PHP to add class to <body> & query param to local links -> CSS class selectors -> CSS variables -> colors & font. No cookies, no JS. #indieweb
hyperlinks -> URL query param -> PHP to add class to <body> & query param to local links -> CSS class selectors -> CSS variables -> colors & font. No cookies, no JS. #indieweb

Fixed an issue in the new Micro.blog themes for IndieWeb-related tags and custom CSS. The great thing about all these themes is that they are completely customizable. Very powerful. But with great power comes… great ability for me to forget important HTML tags.