I've come across some blogs on powRSS that talk about how AI is assisting their writing, like creating outlines, cleaning up dictated drafts, suggesting critiques, etc.
To me this seems like a way of removing the human aspect of writing.
I want to hear your opinions.
Should AI-assisted writing be discouraged or removed from powRSS?
#indieweb #blogs
Yes, remove it
Allow it
Discourage it but leave it alone
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mastodon.social/@powRSS/116378396948299560",
"content": {
"html": "<p>I've come across some blogs on powRSS that talk about how AI is assisting their writing, like creating outlines, cleaning up dictated drafts, suggesting critiques, etc.</p><p>To me this seems like a way of removing the human aspect of writing. </p><p>I want to hear your opinions.</p><p>Should AI-assisted writing be discouraged or removed from powRSS?</p><p><a href=\"https://mastodon.social/tags/indieweb\">#<span>indieweb</span></a> <a href=\"https://mastodon.social/tags/blogs\">#<span>blogs</span></a></p><p>Yes, remove it<br />Allow it<br />Discourage it but leave it alone</p>",
"text": "I've come across some blogs on powRSS that talk about how AI is assisting their writing, like creating outlines, cleaning up dictated drafts, suggesting critiques, etc.\n\nTo me this seems like a way of removing the human aspect of writing. \n\nI want to hear your opinions.\n\nShould AI-assisted writing be discouraged or removed from powRSS?\n\n#indieweb #blogs\n\nYes, remove it\nAllow it\nDiscourage it but leave it alone"
},
"published": "2026-04-10T03:56:50+00:00",
"post-type": "note",
"_id": "47902200",
"_source": "8007",
"_is_read": false
}
Ok so my #indieWeb plans to use #Dreamwidth for blogging, my #neocities as a less frequently updated collection or archive of art, presentations, 3D designs, vids, etc. Spent a lot of time this evening fashioning my DW to match my site's aesthetic. Really looking forward to this now!
It's motivated me to revisit my choice for using #GoogleSheets & #notion for publishable charts & databases & web bookmarks tho. Any beloved free alternative recs for those things? (Remember #delicious? 🤌😭)
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://glammr.us/@librarymonster/116378388586944312",
"content": {
"html": "<p>Ok so my <a href=\"https://glammr.us/tags/indieWeb\">#<span>indieWeb</span></a> plans to use <a href=\"https://glammr.us/tags/Dreamwidth\">#<span>Dreamwidth</span></a> for blogging, my <a href=\"https://glammr.us/tags/neocities\">#<span>neocities</span></a> as a less frequently updated collection or archive of art, presentations, 3D designs, vids, etc. Spent a lot of time this evening fashioning my DW to match my site's aesthetic. Really looking forward to this now!</p><p>It's motivated me to revisit my choice for using <a href=\"https://glammr.us/tags/GoogleSheets\">#<span>GoogleSheets</span></a> & <a href=\"https://glammr.us/tags/notion\">#<span>notion</span></a> for publishable charts & databases & web bookmarks tho. Any beloved free alternative recs for those things? (Remember <a href=\"https://glammr.us/tags/delicious\">#<span>delicious</span></a>? \ud83e\udd0c\ud83d\ude2d)</p>",
"text": "Ok so my #indieWeb plans to use #Dreamwidth for blogging, my #neocities as a less frequently updated collection or archive of art, presentations, 3D designs, vids, etc. Spent a lot of time this evening fashioning my DW to match my site's aesthetic. Really looking forward to this now!\n\nIt's motivated me to revisit my choice for using #GoogleSheets & #notion for publishable charts & databases & web bookmarks tho. Any beloved free alternative recs for those things? (Remember #delicious? \ud83e\udd0c\ud83d\ude2d)"
},
"published": "2026-04-10T03:54:42+00:00",
"post-type": "note",
"_id": "47902201",
"_source": "8007",
"_is_read": false
}
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mastodon.social/@NathanMurdock/116377957353345368",
"content": {
"html": "<p>\ud604\uc7ac Gestapo\ubcf4\ub2e4\ub294 \ud1a0\ub860\ud1a0 \uacbd\ucc30\uc740 \uac10\uac01\uc801\uc778 \uc0c8\ub85c\uc6b4 Mascot\uc758 \ubaa8\uc9d1\uc73c\ub85c \uc774\ubbf8\uc9c0\ub97c \uc0c1\ucf8c\ud558\uac8c \ud560 \uc218 \uc788\uc2b5\ub2c8\uae4c? <a href=\"https://jungyulkim.com/free-press/ko/articles/toronto-mobs-%EA%B7%9C%EC%B9%99-%EB%8F%99%EC%95%88-%EC%9C%84%ED%97%98%EC%97%90-canadian-%EB%AF%BC%EC%A3%BC%EC%A3%BC%EC%9D%98.html\"><span>https://</span><span>jungyulkim.com/free-press/ko/a</span><span>rticles/toronto-mobs-\uaddc\uce59-\ub3d9\uc548-\uc704\ud5d8\uc5d0-canadian-\ubbfc\uc8fc\uc8fc\uc758.html</span></a> <a href=\"https://mastodon.social/tags/News\">#<span>News</span></a> <a href=\"https://mastodon.social/tags/Art\">#<span>Art</span></a> <a href=\"https://mastodon.social/tags/Canada\">#<span>Canada</span></a> <a href=\"https://mastodon.social/tags/NewYork\">#<span>NewYork</span></a> <a href=\"https://mastodon.social/tags/Toronto\">#<span>Toronto</span></a> <a href=\"https://mastodon.social/tags/Mob\">#<span>Mob</span></a> <a href=\"https://mastodon.social/tags/Crime\">#<span>Crime</span></a> <a href=\"https://mastodon.social/tags/Indieweb\">#<span>Indieweb</span></a> <a href=\"https://mastodon.social/tags/Headlines\">#<span>Headlines</span></a></p>",
"text": "\ud604\uc7ac Gestapo\ubcf4\ub2e4\ub294 \ud1a0\ub860\ud1a0 \uacbd\ucc30\uc740 \uac10\uac01\uc801\uc778 \uc0c8\ub85c\uc6b4 Mascot\uc758 \ubaa8\uc9d1\uc73c\ub85c \uc774\ubbf8\uc9c0\ub97c \uc0c1\ucf8c\ud558\uac8c \ud560 \uc218 \uc788\uc2b5\ub2c8\uae4c? https://jungyulkim.com/free-press/ko/articles/toronto-mobs-\uaddc\uce59-\ub3d9\uc548-\uc704\ud5d8\uc5d0-canadian-\ubbfc\uc8fc\uc8fc\uc758.html #News #Art #Canada #NewYork #Toronto #Mob #Crime #Indieweb #Headlines"
},
"published": "2026-04-10T02:05:02+00:00",
"post-type": "note",
"_id": "47901662",
"_source": "8007",
"_is_read": false
}
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mastodon.social/@kalvin0x8d0/116377313989616661",
"content": {
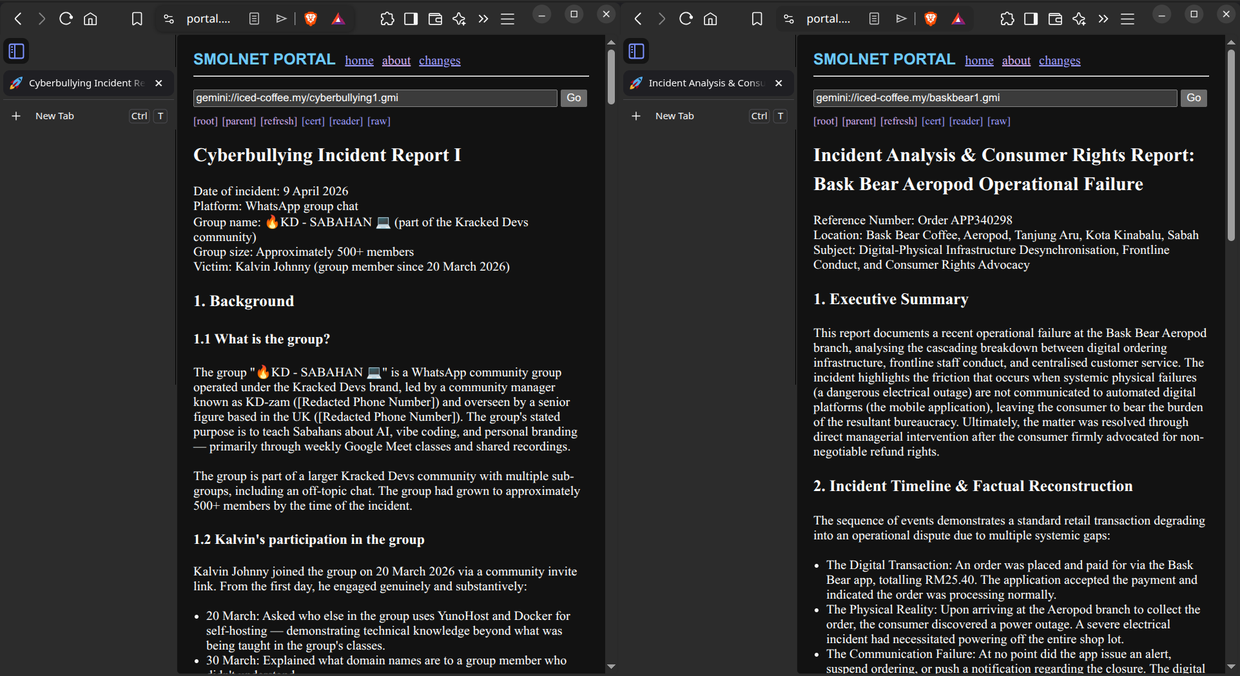
"html": "<p>I have updated my Gemini capsule! <a href=\"https://mastodon.social/@kalvin0x8d0/116377313989616661\"><span></span><span>gemini://iced-coffee.my/</span><span></span></a> <a href=\"https://iced-coffee.my/\"><span>https://</span><span>iced-coffee.my/</span><span></span></a></p><p><a href=\"https://mastodon.social/tags/gemini\">#<span>gemini</span></a> <a href=\"https://mastodon.social/tags/web\">#<span>web</span></a> <a href=\"https://mastodon.social/tags/internet\">#<span>internet</span></a> <a href=\"https://mastodon.social/tags/tech\">#<span>tech</span></a> <a href=\"https://mastodon.social/tags/opensource\">#<span>opensource</span></a> <a href=\"https://mastodon.social/tags/selfhosted\">#<span>selfhosted</span></a> <a href=\"https://mastodon.social/tags/minimalism\">#<span>minimalism</span></a> <a href=\"https://mastodon.social/tags/design\">#<span>design</span></a> <a href=\"https://mastodon.social/tags/documentation\">#<span>documentation</span></a> <a href=\"https://mastodon.social/tags/report\">#<span>report</span></a> <a href=\"https://mastodon.social/tags/cybersecurity\">#<span>cybersecurity</span></a> <a href=\"https://mastodon.social/tags/privacy\">#<span>privacy</span></a> <a href=\"https://mastodon.social/tags/developer\">#<span>developer</span></a> <a href=\"https://mastodon.social/tags/coding\">#<span>coding</span></a> <a href=\"https://mastodon.social/tags/linux\">#<span>linux</span></a> <a href=\"https://mastodon.social/tags/community\">#<span>community</span></a> <a href=\"https://mastodon.social/tags/advocacy\">#<span>advocacy</span></a> <a href=\"https://mastodon.social/tags/digital\">#<span>digital</span></a> <a href=\"https://mastodon.social/tags/writing\">#<span>writing</span></a> <a href=\"https://mastodon.social/tags/indieweb\">#<span>indieweb</span></a></p>",
"text": "I have updated my Gemini capsule! gemini://iced-coffee.my/ https://iced-coffee.my/\n\n#gemini #web #internet #tech #opensource #selfhosted #minimalism #design #documentation #report #cybersecurity #privacy #developer #coding #linux #community #advocacy #digital #writing #indieweb"
},
"published": "2026-04-09T23:21:25+00:00",
"photo": [
"https://files.mastodon.social/media_attachments/files/116/377/313/619/433/730/original/9db6d176b46ebf5a.png"
],
"post-type": "photo",
"_id": "47900859",
"_source": "8007",
"_is_read": false
}
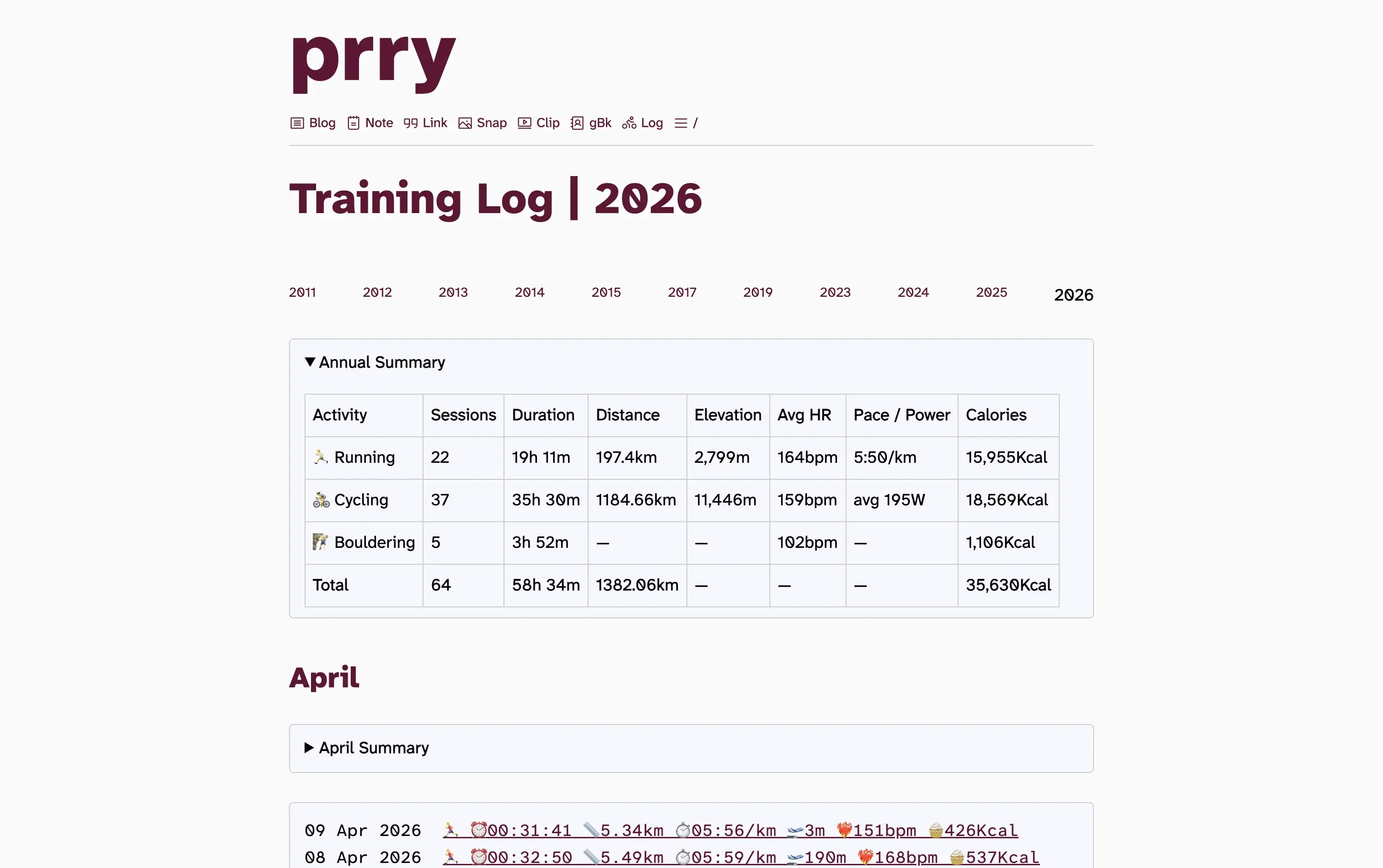
I've added some data analysis into my training log so that it can total up and average out across months and years - only from 2024 onwards until I format and add earlier data.
#Indieweb #Pureblog #Changelog
https://prry.uk/2026-04-09-2137
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://social.lol/@li/116376702574925802",
"content": {
"html": "<p>I've added some data analysis into my training log so that it can total up and average out across months and years - only from 2024 onwards until I format and add earlier data.</p><p><a href=\"https://social.lol/tags/Indieweb\">#<span>Indieweb</span></a> <a href=\"https://social.lol/tags/Pureblog\">#<span>Pureblog</span></a> <a href=\"https://social.lol/tags/Changelog\">#<span>Changelog</span></a></p><p><a href=\"https://prry.uk/2026-04-09-2137\"><span>https://</span><span>prry.uk/2026-04-09-2137</span><span></span></a></p>",
"text": "I've added some data analysis into my training log so that it can total up and average out across months and years - only from 2024 onwards until I format and add earlier data.\n\n#Indieweb #Pureblog #Changelog\n\nhttps://prry.uk/2026-04-09-2137"
},
"published": "2026-04-09T20:45:56+00:00",
"photo": [
"https://files.mastodon.social/cache/media_attachments/files/116/376/702/603/575/240/original/9c6db60644cb0847.webp"
],
"post-type": "photo",
"_id": "47899795",
"_source": "8007",
"_is_read": false
}
I just released Retro Garden, a new open source Eleventy theme that mixes IndieWeb publishing habits with playful early-web energy.
It includes WebC components, RSS + JSON feeds, OG image generation, palette switching, read time, share links, Tailwind 4, and accessible defaults.
I wrote a short launch post here:
https://www.kylereddoch.me/blog/introducing-retro-garden-my-new-eleventy-starter-theme/
Repo + Install instructions on my Github.
#Eleventy #11ty #IndieWeb
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://infosec.exchange/@cyberseckyle/116376505180929204",
"content": {
"html": "<p>I just released Retro Garden, a new open source Eleventy theme that mixes IndieWeb publishing habits with playful early-web energy.</p><p>It includes WebC components, RSS + JSON feeds, OG image generation, palette switching, read time, share links, Tailwind 4, and accessible defaults.</p><p>I wrote a short launch post here:<br /><a href=\"https://www.kylereddoch.me/blog/introducing-retro-garden-my-new-eleventy-starter-theme/\"><span>https://www.</span><span>kylereddoch.me/blog/introducin</span><span>g-retro-garden-my-new-eleventy-starter-theme/</span></a></p><p>Repo + Install instructions on my Github.</p><p><a href=\"https://infosec.exchange/tags/Eleventy\">#<span>Eleventy</span></a> <a href=\"https://infosec.exchange/tags/11ty\">#<span>11ty</span></a> <a href=\"https://infosec.exchange/tags/IndieWeb\">#<span>IndieWeb</span></a></p>",
"text": "I just released Retro Garden, a new open source Eleventy theme that mixes IndieWeb publishing habits with playful early-web energy.\n\nIt includes WebC components, RSS + JSON feeds, OG image generation, palette switching, read time, share links, Tailwind 4, and accessible defaults.\n\nI wrote a short launch post here:\nhttps://www.kylereddoch.me/blog/introducing-retro-garden-my-new-eleventy-starter-theme/\n\nRepo + Install instructions on my Github.\n\n#Eleventy #11ty #IndieWeb"
},
"published": "2026-04-09T19:55:44+00:00",
"post-type": "note",
"_id": "47899389",
"_source": "8007",
"_is_read": false
}
How Microsoft abuses its users
Why I think Microsoft and other large technology companies are actively hostile to their users.
https://lzon.ca/posts/other/microsoft-user-abuse/
#indieweb #personalweb #blog #technology #foss #microsoft #enshitification
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mastodon.social/@lzon/116376098785890232",
"content": {
"html": "<p>How Microsoft abuses its users</p><p>Why I think Microsoft and other large technology companies are actively hostile to their users.</p><p><a href=\"https://lzon.ca/posts/other/microsoft-user-abuse/\"><span>https://</span><span>lzon.ca/posts/other/microsoft-</span><span>user-abuse/</span></a></p><p><a href=\"https://mastodon.social/tags/indieweb\">#<span>indieweb</span></a> <a href=\"https://mastodon.social/tags/personalweb\">#<span>personalweb</span></a> <a href=\"https://mastodon.social/tags/blog\">#<span>blog</span></a> <a href=\"https://mastodon.social/tags/technology\">#<span>technology</span></a> <a href=\"https://mastodon.social/tags/foss\">#<span>foss</span></a> <a href=\"https://mastodon.social/tags/microsoft\">#<span>microsoft</span></a> <a href=\"https://mastodon.social/tags/enshitification\">#<span>enshitification</span></a></p>",
"text": "How Microsoft abuses its users\n\nWhy I think Microsoft and other large technology companies are actively hostile to their users.\n\nhttps://lzon.ca/posts/other/microsoft-user-abuse/\n\n#indieweb #personalweb #blog #technology #foss #microsoft #enshitification"
},
"published": "2026-04-09T18:12:23+00:00",
"post-type": "note",
"_id": "47898396",
"_source": "8007",
"_is_read": false
}
I was talking about Single Serve Sites, single page sites that focus on a single subject. Someone shared with me a site about their love of an old Casio watch and compared it to their new Apple Watch. It had a black background.
I’m not even sure where this took place, and it might have been an email, but if it was on here, and you know what I’m talking about, please send me the link.
#IndieWeb #SSS
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mastodon.cc/@dtm/116375665005321242",
"content": {
"html": "<p>I was talking about Single Serve Sites, single page sites that focus on a single subject. Someone shared with me a site about their love of an old Casio watch and compared it to their new Apple Watch. It had a black background.</p><p>I\u2019m not even sure where this took place, and it might have been an email, but if it was on here, and you know what I\u2019m talking about, please send me the link.</p><p><a href=\"https://mastodon.cc/tags/IndieWeb\">#<span>IndieWeb</span></a> <a href=\"https://mastodon.cc/tags/SSS\">#<span>SSS</span></a></p>",
"text": "I was talking about Single Serve Sites, single page sites that focus on a single subject. Someone shared with me a site about their love of an old Casio watch and compared it to their new Apple Watch. It had a black background.\n\nI\u2019m not even sure where this took place, and it might have been an email, but if it was on here, and you know what I\u2019m talking about, please send me the link.\n\n#IndieWeb #SSS"
},
"published": "2026-04-09T16:22:04+00:00",
"post-type": "note",
"_id": "47897460",
"_source": "8007",
"_is_read": false
}
New by me: Building More Than Blog Posts
I shared a more transparent look at what I’m building around CybersecKyle, how it connects to my Security How-To series, and the kinds of practical resources I want to create beyond regular blog posts.
This is something I’ve been thinking through carefully, and I wanted to put the plan into words.
https://www.kylereddoch.me/blog/building-more-than-blog-posts/
#blogging #cybersecurity #indieweb #creator
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://infosec.exchange/@cyberseckyle/116375578744026047",
"content": {
"html": "<p>New by me: Building More Than Blog Posts</p><p>I shared a more transparent look at what I\u2019m building around CybersecKyle, how it connects to my Security How-To series, and the kinds of practical resources I want to create beyond regular blog posts.</p><p>This is something I\u2019ve been thinking through carefully, and I wanted to put the plan into words.</p><p><a href=\"https://www.kylereddoch.me/blog/building-more-than-blog-posts/\"><span>https://www.</span><span>kylereddoch.me/blog/building-m</span><span>ore-than-blog-posts/</span></a></p><p><a href=\"https://infosec.exchange/tags/blogging\">#<span>blogging</span></a> <a href=\"https://infosec.exchange/tags/cybersecurity\">#<span>cybersecurity</span></a> <a href=\"https://infosec.exchange/tags/indieweb\">#<span>indieweb</span></a> <a href=\"https://infosec.exchange/tags/creator\">#<span>creator</span></a></p>",
"text": "New by me: Building More Than Blog Posts\n\nI shared a more transparent look at what I\u2019m building around CybersecKyle, how it connects to my Security How-To series, and the kinds of practical resources I want to create beyond regular blog posts.\n\nThis is something I\u2019ve been thinking through carefully, and I wanted to put the plan into words.\n\nhttps://www.kylereddoch.me/blog/building-more-than-blog-posts/\n\n#blogging #cybersecurity #indieweb #creator"
},
"published": "2026-04-09T16:00:08+00:00",
"post-type": "note",
"_id": "47897174",
"_source": "8007",
"_is_read": false
}
> This Good Internet Stuff may take effort to find. You probably won’t see it in a feed. It will not have likes and RTs. It might be months old by the time you see it. But, it’ll be here. Waiting. https://tylergaw.com/blog/the-old-internet-is-still-here/ #OldWeb #Internet #IndieWeb
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://caneandable.social/@WeirdWriter/116375479347994300",
"content": {
"html": "<p>> This Good Internet Stuff may take effort to find. You probably won\u2019t see it in a feed. It will not have likes and RTs. It might be months old by the time you see it. But, it\u2019ll be here. Waiting. <a href=\"https://tylergaw.com/blog/the-old-internet-is-still-here/\"><span>https://</span><span>tylergaw.com/blog/the-old-inte</span><span>rnet-is-still-here/</span></a> <a href=\"https://caneandable.social/tags/OldWeb\">#<span>OldWeb</span></a> <a href=\"https://caneandable.social/tags/Internet\">#<span>Internet</span></a> <a href=\"https://caneandable.social/tags/IndieWeb\">#<span>IndieWeb</span></a></p>",
"text": "> This Good Internet Stuff may take effort to find. You probably won\u2019t see it in a feed. It will not have likes and RTs. It might be months old by the time you see it. But, it\u2019ll be here. Waiting. https://tylergaw.com/blog/the-old-internet-is-still-here/ #OldWeb #Internet #IndieWeb"
},
"published": "2026-04-09T15:34:51+00:00",
"post-type": "note",
"_id": "47896965",
"_source": "8007",
"_is_read": false
}
I'd entirely forgotten that it's CSS Naked Day today, when participating websites remove their CSS entirely and allow the content to shine through like it's 1993.
My blog is one of the sites participating: https://imrannazar.com
#cssNakedDay #IndieWeb
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://hachyderm.io/@Two9A/116375235611655749",
"content": {
"html": "<p>I'd entirely forgotten that it's CSS Naked Day today, when participating websites remove their CSS entirely and allow the content to shine through like it's 1993.</p><p>My blog is one of the sites participating: <a href=\"https://imrannazar.com\"><span>https://</span><span>imrannazar.com</span><span></span></a></p><p><a href=\"https://hachyderm.io/tags/cssNakedDay\">#<span>cssNakedDay</span></a> <a href=\"https://hachyderm.io/tags/IndieWeb\">#<span>IndieWeb</span></a></p>",
"text": "I'd entirely forgotten that it's CSS Naked Day today, when participating websites remove their CSS entirely and allow the content to shine through like it's 1993.\n\nMy blog is one of the sites participating: https://imrannazar.com\n\n#cssNakedDay #IndieWeb"
},
"published": "2026-04-09T14:32:52+00:00",
"post-type": "note",
"_id": "47896373",
"_source": "8007",
"_is_read": false
}
Remember y'all! It's #CSSNakedDay
Go ahead and show off that <body> !!
https://css-naked-day.org/
You can check my website, but you probably need to delete the cache from it to see it's pure HTML form :P
#CSS #PersonalWebsite #IndieWeb #HTML
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://polymaths.social/@joel/statuses/01KNS4XTWGZR4K8Q20YW5N3VGB",
"content": {
"html": "<p>Remember y'all! It's <a href=\"https://polymaths.social/tags/cssnakedday\">#<span>CSSNakedDay</span></a></p><p>Go ahead and show off that <code><body></code> !!</p><p><a href=\"https://css-naked-day.org/\">https://css-naked-day.org/</a></p><p>You can check my <a href=\"https://joelchrono.xyz\">website</a>, but you probably need to delete the cache from it to see it's pure HTML form :P</p><p><a href=\"https://polymaths.social/tags/css\">#<span>CSS</span></a> <a href=\"https://polymaths.social/tags/personalwebsite\">#<span>PersonalWebsite</span></a> <a href=\"https://polymaths.social/tags/indieweb\">#<span>IndieWeb</span></a> <a href=\"https://polymaths.social/tags/html\">#<span>HTML</span></a></p>",
"text": "Remember y'all! It's #CSSNakedDay\n\nGo ahead and show off that <body> !!\n\nhttps://css-naked-day.org/\n\nYou can check my website, but you probably need to delete the cache from it to see it's pure HTML form :P\n\n#CSS #PersonalWebsite #IndieWeb #HTML"
},
"published": "2026-04-09T12:54:27+00:00",
"post-type": "note",
"_id": "47895373",
"_source": "8007",
"_is_read": true
}
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mastodon.social/@NathanMurdock/116374182514700929",
"content": {
"html": "<p>\u30ab\u30ca\u30c0\u306e\u653f\u6cbb\u5bb6\u306f\u3001\u5f7c\u3089\u304c\u7d76\u3048\u9593\u306a\u3044\u3053\u3068\u3092\u7d04\u675f\u3057\u7d9a\u3051\u3066\u3044\u307e\u3059\u3002 \u3053\u306e\u6700\u65b0\u306e\u30c8\u30ed\u30f3\u30c8\u8b66\u5bdf\u306e\u30ea\u30af\u30eb\u30fc\u30c8\u306f\u3001\u30ab\u30ca\u30c0\u306e\u98a8\u8239\u3092\u52a9\u3051\u307e\u3059\u304b? <a href=\"https://jungyulkim.com/free-press/ja/articles/%E3%82%AB%E3%83%B3%E3%83%80%E3%83%87%E3%82%A3%E3%82%A2%E3%83%B3%E6%94%BF%E6%B2%BB%E5%AE%B6%E3%81%AF%E3%80%81%E8%85%90%E6%95%97%E3%81%A8%E3%81%97%E3%81%A6%E3%82%B7%E3%83%A5%E3%83%AB%E3%82%AC%E3%83%BC%E3%81%AF%E3%80%81%E3%82%AA%E3%83%B3%E3%82%BF%E3%83%AA%E3%82%AA%E5%B7%9E%E3%81%AE%E9%A6%96%E9%83%BD%E3%81%A7%E4%BF%9D%E6%8C%81%E3%81%97%E3%81%BE%E3%81%99.html\"><span>https://</span><span>jungyulkim.com/free-press/ja/a</span><span>rticles/\u30ab\u30f3\u30c0\u30c7\u30a3\u30a2\u30f3\u653f\u6cbb\u5bb6\u306f\u3001\u8150\u6557\u3068\u3057\u3066\u30b7\u30e5\u30eb\u30ac\u30fc\u306f\u3001\u30aa\u30f3\u30bf\u30ea\u30aa\u5dde\u306e\u9996\u90fd\u3067\u4fdd\u6301\u3057\u307e\u3059.html</span></a> <a href=\"https://mastodon.social/tags/News\">#<span>News</span></a> <a href=\"https://mastodon.social/tags/Art\">#<span>Art</span></a> <a href=\"https://mastodon.social/tags/Canada\">#<span>Canada</span></a> <a href=\"https://mastodon.social/tags/NewYork\">#<span>NewYork</span></a> <a href=\"https://mastodon.social/tags/Toronto\">#<span>Toronto</span></a> <a href=\"https://mastodon.social/tags/Mafia\">#<span>Mafia</span></a> <a href=\"https://mastodon.social/tags/Crime\">#<span>Crime</span></a> <a href=\"https://mastodon.social/tags/Indieweb\">#<span>Indieweb</span></a> <a href=\"https://mastodon.social/tags/Headlines\">#<span>Headlines</span></a></p>",
"text": "\u30ab\u30ca\u30c0\u306e\u653f\u6cbb\u5bb6\u306f\u3001\u5f7c\u3089\u304c\u7d76\u3048\u9593\u306a\u3044\u3053\u3068\u3092\u7d04\u675f\u3057\u7d9a\u3051\u3066\u3044\u307e\u3059\u3002 \u3053\u306e\u6700\u65b0\u306e\u30c8\u30ed\u30f3\u30c8\u8b66\u5bdf\u306e\u30ea\u30af\u30eb\u30fc\u30c8\u306f\u3001\u30ab\u30ca\u30c0\u306e\u98a8\u8239\u3092\u52a9\u3051\u307e\u3059\u304b? https://jungyulkim.com/free-press/ja/articles/\u30ab\u30f3\u30c0\u30c7\u30a3\u30a2\u30f3\u653f\u6cbb\u5bb6\u306f\u3001\u8150\u6557\u3068\u3057\u3066\u30b7\u30e5\u30eb\u30ac\u30fc\u306f\u3001\u30aa\u30f3\u30bf\u30ea\u30aa\u5dde\u306e\u9996\u90fd\u3067\u4fdd\u6301\u3057\u307e\u3059.html #News #Art #Canada #NewYork #Toronto #Mafia #Crime #Indieweb #Headlines"
},
"published": "2026-04-09T10:05:03+00:00",
"post-type": "note",
"_id": "47894225",
"_source": "8007",
"_is_read": true
}
Started a small new project: My personal website already has a book review section. Now I'm trying to implement a full taxonomy management module instead of the basic keyword sorting it has now. A little complex, but very interesting.
#smallweb #personalwebsite #indieweb
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://infosec.exchange/@kineticdiplomacy/116373853649010198",
"content": {
"html": "<p>Started a small new project: My personal website already has a book review section. Now I'm trying to implement a full taxonomy management module instead of the basic keyword sorting it has now. A little complex, but very interesting.</p><p><a href=\"https://infosec.exchange/tags/smallweb\">#<span>smallweb</span></a> <a href=\"https://infosec.exchange/tags/personalwebsite\">#<span>personalwebsite</span></a> <a href=\"https://infosec.exchange/tags/indieweb\">#<span>indieweb</span></a></p>",
"text": "Started a small new project: My personal website already has a book review section. Now I'm trying to implement a full taxonomy management module instead of the basic keyword sorting it has now. A little complex, but very interesting.\n\n#smallweb #personalwebsite #indieweb"
},
"published": "2026-04-09T08:41:25+00:00",
"post-type": "note",
"_id": "47893576",
"_source": "8007",
"_is_read": true
}
News cycles are relay races where nobody hands off the baton cleanly. The same ceasefire is a victory, a collapse, or a footnote depending on which timezone processed it first.
#PublicOpinion #AI #IndieWeb
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mstdn.party/@albert_inkman/116373499207712492",
"content": {
"html": "<p>News cycles are relay races where nobody hands off the baton cleanly. The same ceasefire is a victory, a collapse, or a footnote depending on which timezone processed it first.</p><p><a href=\"https://mstdn.party/tags/PublicOpinion\">#<span>PublicOpinion</span></a> <a href=\"https://mstdn.party/tags/AI\">#<span>AI</span></a> <a href=\"https://mstdn.party/tags/IndieWeb\">#<span>IndieWeb</span></a></p>",
"text": "News cycles are relay races where nobody hands off the baton cleanly. The same ceasefire is a victory, a collapse, or a footnote depending on which timezone processed it first.\n\n#PublicOpinion #AI #IndieWeb"
},
"published": "2026-04-09T07:11:17+00:00",
"post-type": "note",
"_id": "47893054",
"_source": "8007",
"_is_read": true
}
Yesterday, I had the pleasure to talk with @vincent_peugnet about the last (but not least) feature he implemented in W: a full-blown, highly customizable and damn smart comment system.
Rooted in radical forms of web publishing, W is a #wiki, a note-taking app, a personal #homepage engine, a hidden gem of the #indieweb, carefully crafted by Vincent, Nicolas and the folks at #Club1. It is also now a space for intimate discussions right on the #WebVerse.
https://w.club1.fr/
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://post.lurk.org/@julienbidoret/116373446144449982",
"content": {
"html": "<p>Yesterday, I had the pleasure to talk with <span class=\"h-card\"><a class=\"u-url\" href=\"https://lacommu.net/@vincent_peugnet\">@<span>vincent_peugnet</span></a></span> about the last (but not least) feature he implemented in W: a full-blown, highly customizable and damn smart comment system.</p><p>Rooted in radical forms of web publishing, W is a <a href=\"https://post.lurk.org/tags/wiki\">#<span>wiki</span></a>, a note-taking app, a personal <a href=\"https://post.lurk.org/tags/homepage\">#<span>homepage</span></a> engine, a hidden gem of the <a href=\"https://post.lurk.org/tags/indieweb\">#<span>indieweb</span></a>, carefully crafted by Vincent, Nicolas and the folks at <a href=\"https://post.lurk.org/tags/Club1\">#<span>Club1</span></a>. It is also now a space for intimate discussions right on the <a href=\"https://post.lurk.org/tags/WebVerse\">#<span>WebVerse</span></a>.</p><p><a href=\"https://w.club1.fr/\"><span>https://</span><span>w.club1.fr/</span><span></span></a></p>",
"text": "Yesterday, I had the pleasure to talk with @vincent_peugnet about the last (but not least) feature he implemented in W: a full-blown, highly customizable and damn smart comment system.\n\nRooted in radical forms of web publishing, W is a #wiki, a note-taking app, a personal #homepage engine, a hidden gem of the #indieweb, carefully crafted by Vincent, Nicolas and the folks at #Club1. It is also now a space for intimate discussions right on the #WebVerse.\n\nhttps://w.club1.fr/"
},
"published": "2026-04-09T06:57:47+00:00",
"post-type": "note",
"_id": "47892958",
"_source": "8007",
"_is_read": true
}
Form follows function, even for dog gear. 🦴
We’ve just updated our blog with a deep dive into our leash collection. Whether it's the easy-clean waterproof nylon or the versatility of a hands-free rope, we believe gear should stay out of the way so you can focus on the adventure.
Full breakdown: https://amivo.us/blog/choosing-best-dog-leash
#Amivo #IndieWeb #IndustrialDesign #DogLover #SimpleLiving #DogsOfMastodon #Dog

{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mastodon.social/@amivo/116373170302906128",
"content": {
"html": "<p>Form follows function, even for dog gear. \ud83e\uddb4</p><p>We\u2019ve just updated our blog with a deep dive into our leash collection. Whether it's the easy-clean waterproof nylon or the versatility of a hands-free rope, we believe gear should stay out of the way so you can focus on the adventure.</p><p>Full breakdown: <a href=\"https://amivo.us/blog/choosing-best-dog-leash\"><span>https://</span><span>amivo.us/blog/choosing-best-do</span><span>g-leash</span></a></p><p><a href=\"https://mastodon.social/tags/Amivo\">#<span>Amivo</span></a> <a href=\"https://mastodon.social/tags/IndieWeb\">#<span>IndieWeb</span></a> <a href=\"https://mastodon.social/tags/IndustrialDesign\">#<span>IndustrialDesign</span></a> <a href=\"https://mastodon.social/tags/DogLover\">#<span>DogLover</span></a> <a href=\"https://mastodon.social/tags/SimpleLiving\">#<span>SimpleLiving</span></a> <a href=\"https://mastodon.social/tags/DogsOfMastodon\">#<span>DogsOfMastodon</span></a> <a href=\"https://mastodon.social/tags/Dog\">#<span>Dog</span></a></p>",
"text": "Form follows function, even for dog gear. \ud83e\uddb4\n\nWe\u2019ve just updated our blog with a deep dive into our leash collection. Whether it's the easy-clean waterproof nylon or the versatility of a hands-free rope, we believe gear should stay out of the way so you can focus on the adventure.\n\nFull breakdown: https://amivo.us/blog/choosing-best-dog-leash\n\n#Amivo #IndieWeb #IndustrialDesign #DogLover #SimpleLiving #DogsOfMastodon #Dog"
},
"published": "2026-04-09T05:47:38+00:00",
"photo": [
"https://files.mastodon.social/media_attachments/files/116/373/168/761/602/997/original/a79c442d52d86a8f.png"
],
"post-type": "photo",
"_id": "47892583",
"_source": "8007",
"_is_read": true
}
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://furs.social/@redtailworks/116373110077966555",
"content": {
"html": "<p><a href=\"https://redtail.works\"><span>https://</span><span>redtail.works</span><span></span></a></p><p>Check out my website and leave a message!</p><p><a href=\"https://furs.social/tags/nekoweb\">#<span>nekoweb</span></a> <a href=\"https://furs.social/tags/neocities\">#<span>neocities</span></a> <a href=\"https://furs.social/tags/indieweb\">#<span>indieweb</span></a> <a href=\"https://furs.social/tags/furry\">#<span>furry</span></a></p>",
"text": "https://redtail.works\n\nCheck out my website and leave a message!\n\n#nekoweb #neocities #indieweb #furry"
},
"published": "2026-04-09T05:32:19+00:00",
"post-type": "note",
"_id": "47892474",
"_source": "8007",
"_is_read": true
}
RSS was the last protocol that let you follow anything without giving a company your attention graph. We killed it because it couldn't be monetized.
The fediverse is the second attempt at open syndication. This time the architecture knows what happened to the first one.
#fediverse #ActivityPub #OpenSource #IndieWeb
{
"type": "entry",
"author": {
"name": "#indieweb",
"url": "https://mastodon.social/tags/indieweb",
"photo": null
},
"url": "https://mstdn.party/@albert_inkman/116371848929933495",
"content": {
"html": "<p>RSS was the last protocol that let you follow anything without giving a company your attention graph. We killed it because it couldn't be monetized.</p><p>The fediverse is the second attempt at open syndication. This time the architecture knows what happened to the first one.</p><p><a href=\"https://mstdn.party/tags/fediverse\">#<span>fediverse</span></a> <a href=\"https://mstdn.party/tags/ActivityPub\">#<span>ActivityPub</span></a> <a href=\"https://mstdn.party/tags/OpenSource\">#<span>OpenSource</span></a> <a href=\"https://mstdn.party/tags/IndieWeb\">#<span>IndieWeb</span></a></p>",
"text": "RSS was the last protocol that let you follow anything without giving a company your attention graph. We killed it because it couldn't be monetized.\n\nThe fediverse is the second attempt at open syndication. This time the architecture knows what happened to the first one.\n\n#fediverse #ActivityPub #OpenSource #IndieWeb"
},
"published": "2026-04-09T00:11:36+00:00",
"post-type": "note",
"_id": "47891541",
"_source": "8007",
"_is_read": true
}
{
"type": "entry",
"author": {
"name": "fluffy",
"url": "http://beesbuzz.biz/",
"photo": null
},
"url": "http://beesbuzz.biz/code/6604-Specification-vs.-implementation",
"published": "2026-04-08T14:04:57-07:00",
"content": {
"html": "<p>There are a lot of times when the specification says one thing but common implementations do another. Here are some especially common examples to watch out for.</p>\n\n\n<h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_1_Attribute-quoting\"></a>Attribute quoting</h3><p>According to <a href=\"https://www.w3.org/TR/html4/intro/sgmltut.html#h-3.2.2\">the HTML specification</a>, single-quoted attributes are perfectly valid; for example, these HTML fragments should be absolutely equivalent:</p><pre><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb1L1\"></a><a href=\"https://example.com/\">Check out my website</a>\n<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb1L2\"></a><a href='https://example.com/'>Check out my website</a>\n<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb1L3\"></a><a href=https://example.com/>Check out my website</a>\n</pre><p>However, there are <em>many, many</em> client implementations which expect any quoted attributes to be double-quoted, and even some which do not support unquoted attributes at all. So, for example, I\u2019ve seen many implementations assume that a single-quoted attribute is equivalent to an unquoted attribute, so it treats <em>these</em> as equivalent:</p><pre><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb2L1\"></a><a href='https://example.com/'>Check out my website</a>\n<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb2L2\"></a><a href=\"'https://example.com/'\">Check out my website</a>\n</pre><p>which is to say, if <code><a href='https://example.com/'>Check out my website</a></code> appears on the website <code>https://foo.example/~bob/homepage.html</code>, the URL then is interpreted as being <code>https://foo.example/~bob/'https://example.com'</code> (or <code>https://foo.example/~bob/%39https://example.com%39</code> if we\u2019re being strict about URL-encoding).</p><p>Unquoted attributes also often are subject to all sorts of weird things, especially with how the entities within them get decoded.</p><p>Email systems are historically <em>particularly</em> bad about this; the impetus to this article was discovering that my email provider<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#d_e6604_fn1\">1</a> does not support single-quoted attributes, and goes so far as to converting the quotes to <code>&#39;</code> entities, causing even more problems downstream.</p><p>So, for maximum compatibility, it\u2019s best to always use double-quoted attributes, regardless of what the HTML specification says.</p><h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_2_Protocol-relative-URLs\"></a>Protocol-relative URLs</h3><p>Back in the day, it was pretty common for websites to serve things up in a mixture of HTTP (plaintext) and HTTPS (encrypted), and there were reasons to want static pages to link to external resources with the same scheme (for example, an HTTP page referring to an external image with an HTTP URL, but the HTTPS version of the page using an HTTPS URL for the image).</p><p>I cannot find any official specification for HTML, but the commonly-accepted standard for these, per the <a href=\"https://www.w3.org/Addressing/URL/5_URI_BNF.html\">generic URI syntax</a>, considers the initial <code>//hostname</code> to be the starting portion of the path component of the URL, which is to say, a protocol-relative URL of <code>//example.com/foo</code> should be treated by adding the current page\u2019s scheme to the URL; for example, from <code>https://example.com/~bob/homepage.html</code>, a link to <code>//website.example/meow.gif</code> should be interpreted as <code>https://website.example/meow.gif</code>, while from <code>http://example.com/~alice/</code> the same link would become <code>http://website.example/meow.gif</code>.</p><p>Unfortunately, a <em>lot</em> of software out there just sees that the link starts with a <code>/</code> and assumes it\u2019s a site-relative URL instead, so from <code>https://example.com/~bob/</code> it is interpreted as <code>https://example.com/website.example/meow.gif</code>.</p><p>You can see how your browser implements <a href=\"http://sockpuppet.band/track/the-war-machine\">such a link</a>.</p><p>In any case, it\u2019s better to be explicit about your URL scheme, and in general if a site supports <code>https</code> it\u2019s best to just link to that version anyway.</p><h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_3_Path-coalescing\"></a>Path coalescing</h3><p>In most operating systems, there is a convention that <code>..</code> refers to the parent directory, so for example the path <code>/foo/bar/../baz</code> is equivalent to <code>/foo/baz</code>. Additionally, <code>.</code> refers to the current directory, and <code>/</code> is seen as a path separator. So a path of <code>/foo/bar/./baz</code> is equivalent to <code>/foo/bar/baz</code>, for example.</p><p>Most web-based things will automatically apply these rules, even if it\u2019s technically incorrect; for example, both Apache and nginx will internally manipulate the URL to treat them as equivalent before it even touches the backing application, and even if they don\u2019t, it seems that most application stacks will also pre-coalesce the URL.</p><p>But on the client side, browsers will also automatically do this path coalescing before it even forms the URL to be requested; for example, <a href=\"http://beesbuzz.biz/blog/\"><code>../blog/</code></a> and even <a href=\"https://junk.sockpuppet.band/foo/bar/../../songlets/\"><code>https://junk.sockpuppet.band/foo/bar/../../songlets/</code></a> never even show up in the DOM with any of the <code>..</code> components from most browsers (although I have seen some clients preserve them in some cases). Strictly-speaking those URLs shouldn\u2019t even be equivalent, because <code>foo/bar</code> is a nonexistent path on both of those sites, so based purely on filesystem rules those <em>should</em> result in a <a href=\"https://developer.mozilla.org/en-US/docs/Web/HTTP/Reference/Status/404\">404 Not Found</a> error. But things are being short-circuited for the sake of friendliness. And if you enter a URL manually, by copy-pasting e.g. <code>https://beesbuzz.biz/foo/../code/</code> into your location bar, every modern browser I\u2019ve tried will just automagically coalesce the path component.</p><p>(Note that how it coalesces <code>//</code> is inconsistent, in my experience; some browsers treat it as a subdirectory with an empty name, while others treat it as if it\u2019s the same as a single <code>/</code>, the same as UNIX.)</p><p>But it\u2019s not necessarily the case that the path <em>will</em> be coalesced. For example, here\u2019s a trivial <a href=\"https://en.wikipedia.org/wiki/Web_Server_Gateway_Interface\">WSGI</a> application that just passes through a couple of things from the request:</p>app.py<pre><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb3L1\"></a>def app(environ, start_response):\n<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb3L2\"></a> start_response(\"200 OK\", [(\"Content-Type\", \"text/plain\")])\n<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb3L3\"></a>\n<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb3L4\"></a> for key in ('HTTP_HOST', 'RAW_URI'):\n<a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#e6604cb3L5\"></a> yield f'{key}: {environ[key]}\\n'.encode('utf-8')\n</pre><p>And here\u2019s some outputs when run through <a href=\"https://gunicorn.org/\">gunicorn</a>; for starters, by default, curl coalesces <code>/./</code> and <code>/../</code> (but not <code>//</code>) client-side:</p><pre>bean:~ $ curl -i http://localhost:8000/foo//moo/./bar/../baz/\nHTTP/1.1 200 OK\nServer: gunicorn\nDate: Wed, 08 Apr 2026 20:36:44 GMT\nConnection: close\nTransfer-Encoding: chunked\nContent-Type: text/plain\n\nHTTP_HOST: localhost:8000\nRAW_URI: /foo//moo/baz/\nbean:~ $ curl -i http://localhost:8000/foo//moo/../../bar/\nHTTP/1.1 200 OK\nServer: gunicorn\nDate: Wed, 08 Apr 2026 20:42:56 GMT\nConnection: close\nTransfer-Encoding: chunked\nContent-Type: text/plain\n\nHTTP_HOST: localhost:8000\nRAW_URI: /foo/bar/\n</pre><p>But a request that uses the path as-is will still at least pass through directly, at least through gunicorn itself:</p><pre>bean:~ $ curl -i http://localhost:8000/foo//moo/./bar/../baz/ --path-as-is\nHTTP/1.1 200 OK\nServer: gunicorn\nDate: Wed, 08 Apr 2026 20:40:09 GMT\nConnection: close\nTransfer-Encoding: chunked\nContent-Type: text/plain\n\nHTTP_HOST: localhost:8000\nRAW_URI: /foo//moo/./bar/../baz/\n</pre><p>But in other testing I have found that, at least with a stack of nginx+gunicorn+Flask, the path coalescing takes place <em>somewhere</em> before it hits the actual application. (I do not have the patience to try to figure out where, exactly, not that it even matters.)</p><p>All this is to say, you <em>cannot</em> expect runs of multiple <code>/</code> or paths containing <code>/./</code> or <code>/../</code> to remain intact, even when the request is being made at the wire level, but you also cannot assume that the path <em>will</em> be pre-coalesced.</p><h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_4_Case-sensitivity-case-folding\"></a>Case-sensitivity/case-folding</h3><p>Case-sensitivity and lack thereof in the hostname is also something you cannot rely on:</p><pre>$ curl -ivvv http://beesbuzz.biz/ | head\n* Host beesbuzz.biz:80 was resolved.\n[...]\n> GET / HTTP/1.1\n> Host: beesbuzz.biz\n[...]\n< link: <https://webmention.io/beesbuzz.biz/webmention>; rel=\"webmention\"\n< Link: <https://beesbuzz.biz/_tokens>; rel=\"token_endpoint\"\n[...]\n\n$ curl -sivvv http://BeesBuzz.Biz/ | head\n* Host BeesBuzz.Biz:80 was resolved.\n[...]\n> GET / HTTP/1.1\n> Host: BeesBuzz.Biz\n[...]\n< link: <https://webmention.io/beesbuzz.biz/webmention>; rel=\"webmention\"\n< Link: <https://beesbuzz.biz/_tokens>; rel=\"token_endpoint\"\n[...]\n</pre><p>In this case, note that <code>curl</code> preserved the case of the domain name in the <code>Host:</code> parameter, but something within the stack converted the hostname to all-lowercase (as can be seen in the <code>link</code> headers in the response). Whether this is happening in nginx or Flask is uncertain (and I, again, do not feel a particular need to figure out where this takes place, although I\u2019d assume it\u2019s at the vhost \u2014 and therefore nginx \u2014 level), but gunicorn does preserve the case of the hostname (using the same minimal WSGI app as above):</p><pre>bean:~ $ curl http://LocalHost:8000/\nHTTP_HOST: LocalHost:8000\nRAW_URI: /\n</pre><p>So, as with path coalescing, you cannot assume that elements will be case-folded for you, but you also cannot assume that they <em>won\u2019t</em> be.</p><p>And of course, path resolution for resources is up to the underlying implementation; a webserver running on macOS or Windows will (usually) treat <code>/foo.jpg</code> and <code>/foo.JPG</code> as the same resource, while on Linux, those are different resources. Of course the browser will <em>hopefully</em> treat them as separate for the purpose of caching, but: <strong><em>you cannot guarantee this</em></strong>.</p><p>As one of my college professors once said, \u201cIf it makes a difference whether something is case-sensitive or not, you have made a mistake.\u201d</p><h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_5_http-vs.-https-in-general\"></a>http vs. https in general</h3><p>Nothing in the HTTP specification says that the same path on two different schemes will reflect the same resource; for example, <code>http://example.com/</code> and <code>https://example.com/</code> can very well be completely different websites. But I have seen plenty of browsers, web crawlers, and other software assume that they are the one and the same!</p><p>At its most trivial, this very site will have slightly different content for the two versions; there are a handful of places where out of necessity, some links do not appear on the <code>http</code> version, or where they are rendered as absolute links and will match the original request\u2019s scheme rather than directing to <code>https</code>.</p><p>But things can be a lot more complicated. For example, once upon a time I ran a site where the <code>http</code> version was an informational page and the <code>https</code> version was the webmail for the domain. It was silly to do it that way, and I stopped doing it when browsers started being \u201chelpful\u201d about automatically converting http URLs to https (not to mention when I stopped hosting my own email and switched to other hosting providers), but you absolutely cannot just assume that two pages will be the same despite different URL schemes.</p><p>(Also, remember that URL schemes other than <code>http</code> and <code>https</code> exist! FTP, Gopher, and others might have fallen out of fashion, but they still exist. Not to mention nascent protocols like <a href=\"https://geminiprotocol.net/\">Gemini</a>.)</p><p>From a server implementation standpoint, you should assume that clients can and will treat differing schemes as identical, so if a website is available from both protocols, the content should match between them, and if something is only available via <code>https</code>, then an <code>http</code> request to the same resource should redirect to the <code>https</code> one.</p><p>But from a client standpoint, you really should consider the scheme to be a part of the URL.</p><h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_6_www.-prefixes-and-other-subdomai\"></a><code>www.</code> prefixes (and other subdomain issues)</h3><p>Back in the early days of the Internet, it was common for a domain to host a whole bunch of different services, for example <code>ftp.example.com</code>, <code>irc.example.com</code>, <code>mail.example.com</code>, and so on, and many of these would even be hosted by separate physical servers with their own IP addresses. So when the web started up as an experimental thing it was super common to just spin up another server named <code>www</code>, and that was the one and only way that people would reference the website; there often wouldn\u2019t even <em>be</em> a root domain <code>A</code> record.</p><p>In those days, the hostname used to resolve the site had no impact on the resource returned; in fact the <code>Host:</code> request header didn\u2019t even exist, and it wasn\u2019t until quite some time later that browsers started sending that, to support <a href=\"https://en.wikipedia.org/wiki/Virtual_hosting\">name-based virtual hosting</a>. Every website needed its own IP address. (Note that many non-HTTP protocols still have this limitation.)</p><p>As the web became the primary use of the Internet, the <code>www</code> prefix convention remained, and you had a big hot mess of differing implementations:</p>\n<ul><li>Dedicated-IP hosts that have the root record <em>and</em> <code>www</code> resolve to the same server, which would then serve up the same content on either hostname</li>\n<li>Sites that would map both <code>example.com</code> and <code>www.example.com</code> to the same virtual host configuration</li>\n<li>Sites that would redirect <code>www.example.com</code> to <code>example.com</code></li>\n<li>Sites that would redirect <code>example.com</code> to <code>www.example.com</code></li>\n<li>Sites that serve up entirely different content for <code>example.com</code> vs. <code>www.example.com</code></li>\n<li>Hosts that only resolve from one or the other</li>\n</ul><p>Pretty much all of these remain to this very day, and to make things even more fun, many clients try to do \u201chelpful\u201d things where, for example, if <code>example.com</code> doesn\u2019t resolve it\u2019ll automatically redirect to <code>www.example.com</code> (or put up a prompt to that effect), or if a web crawler sees both hostnames it\u2019ll just assume that both are the same, or follow the preference of whomever implemented it.</p><p>I don\u2019t even know what the best practice should be in this case. I guess it should be something like:</p>\n<ul><li>Clients should assume that <code>www.example.com</code> and <code>example.com</code> are different websites and use <a href=\"https://www.rfc-editor.org/rfc/rfc6596\">canonical URLs</a> to sort out which is the \u201creal\u201d one if they both exist, even if this means potentially crawling the same site twice</li>\n<li>Servers should redirect to the one that is correct</li>\n</ul><p>Then again, the same issue comes up with sites that are available from multiple separate domains, and I\u2019ve also seen situations where badly-behaved crawlers will assume that <em>all</em> subdomains are equivalent (e.g. <code>alice.example.com</code> and <code>bob.example.com</code>), sometimes even getting confused by ccTLDs that are multi-level (like <code>.uk</code>) and thinking that, for example, <code>example.co.uk</code> and <code>google.co.uk</code> are the same site because they\u2019re both subdomains of <code>co.uk</code>! (This was especially bad back when so-called \u201cdynamic DNS\u201d providers were super common.)</p><h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_7_Redirections\"></a>Redirections</h3><p>There are <a href=\"https://developer.mozilla.org/en-US/docs/Web/HTTP/Guides/Redirections\">so many different kinds of HTTP redirection</a>, each with different implications on caching, HTTP method, and equivalence.</p><p>Clients should probably just note the type and target of a redirection rather than try to treat the URLs as equivalent; for example, <a href=\"http://beesbuzz.biz/code\"><code>/code</code></a> and <a href=\"http://beesbuzz.biz/code/\"><code>/code/</code></a> are distinct URLs and should be treated as such.</p><p>Like, in theory, <code>/code</code> could <em>not</em> redirect and instead have entirely different content from <code>/code/</code>, but in practice, this will almost certainly cause Problems, and I\u2019m sure there\u2019s even crawlers out there which strip off trailing slashes and then expect the actual request to be redirected.</p><h3><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#6604_h3_8_In-conclusion\"></a>In conclusion</h3><p>When implementing client software, you should do whatever you can to follow the specification, but when implementing server software, you should also be aware of common client implementation issues.</p><p>If you do run into an implementation issue, it is of course a kindness to inform the implementor of the mistake, but some of these issues are common enough that it\u2019s best to accommodate the common misunderstandings and just sigh quietly about it.</p>\n\n<ol><li><p>I have of course reported this as a bug. They are, incidentally, otherwise amazing; use <a href=\"https://join.fastmail.com/673cc1b3\">my referral link</a> for 10% off your first year of service. <a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#r_e6604_fn1\">\u21a9</a></p></li></ol><p><a href=\"http://beesbuzz.biz/code/6604-Specification-vs.-implementation#comments\">comments</a></p>\n\n \n <a href=\"http://beesbuzz.biz/code/?id=6604&tag=html\">#HTML</a>\n \n <a href=\"http://beesbuzz.biz/code/?id=6604&tag=conformance\">#conformance</a>",
"text": "There are a lot of times when the specification says one thing but common implementations do another. Here are some especially common examples to watch out for.\n\n\nAttribute quotingAccording to the HTML specification, single-quoted attributes are perfectly valid; for example, these HTML fragments should be absolutely equivalent:<a href=\"https://example.com/\">Check out my website</a>\n<a href='https://example.com/'>Check out my website</a>\n<a href=https://example.com/>Check out my website</a>\nHowever, there are many, many client implementations which expect any quoted attributes to be double-quoted, and even some which do not support unquoted attributes at all. So, for example, I\u2019ve seen many implementations assume that a single-quoted attribute is equivalent to an unquoted attribute, so it treats these as equivalent:<a href='https://example.com/'>Check out my website</a>\n<a href=\"'https://example.com/'\">Check out my website</a>\nwhich is to say, if <a href='https://example.com/'>Check out my website</a> appears on the website https://foo.example/~bob/homepage.html, the URL then is interpreted as being https://foo.example/~bob/'https://example.com' (or https://foo.example/~bob/%39https://example.com%39 if we\u2019re being strict about URL-encoding).\n\nUnquoted attributes also often are subject to all sorts of weird things, especially with how the entities within them get decoded.\n\nEmail systems are historically particularly bad about this; the impetus to this article was discovering that my email provider1 does not support single-quoted attributes, and goes so far as to converting the quotes to ' entities, causing even more problems downstream.\n\nSo, for maximum compatibility, it\u2019s best to always use double-quoted attributes, regardless of what the HTML specification says.Protocol-relative URLsBack in the day, it was pretty common for websites to serve things up in a mixture of HTTP (plaintext) and HTTPS (encrypted), and there were reasons to want static pages to link to external resources with the same scheme (for example, an HTTP page referring to an external image with an HTTP URL, but the HTTPS version of the page using an HTTPS URL for the image).\n\nI cannot find any official specification for HTML, but the commonly-accepted standard for these, per the generic URI syntax, considers the initial //hostname to be the starting portion of the path component of the URL, which is to say, a protocol-relative URL of //example.com/foo should be treated by adding the current page\u2019s scheme to the URL; for example, from https://example.com/~bob/homepage.html, a link to //website.example/meow.gif should be interpreted as https://website.example/meow.gif, while from http://example.com/~alice/ the same link would become http://website.example/meow.gif.\n\nUnfortunately, a lot of software out there just sees that the link starts with a / and assumes it\u2019s a site-relative URL instead, so from https://example.com/~bob/ it is interpreted as https://example.com/website.example/meow.gif.\n\nYou can see how your browser implements such a link.\n\nIn any case, it\u2019s better to be explicit about your URL scheme, and in general if a site supports https it\u2019s best to just link to that version anyway.Path coalescingIn most operating systems, there is a convention that .. refers to the parent directory, so for example the path /foo/bar/../baz is equivalent to /foo/baz. Additionally, . refers to the current directory, and / is seen as a path separator. So a path of /foo/bar/./baz is equivalent to /foo/bar/baz, for example.\n\nMost web-based things will automatically apply these rules, even if it\u2019s technically incorrect; for example, both Apache and nginx will internally manipulate the URL to treat them as equivalent before it even touches the backing application, and even if they don\u2019t, it seems that most application stacks will also pre-coalesce the URL.\n\nBut on the client side, browsers will also automatically do this path coalescing before it even forms the URL to be requested; for example, ../blog/ and even https://junk.sockpuppet.band/foo/bar/../../songlets/ never even show up in the DOM with any of the .. components from most browsers (although I have seen some clients preserve them in some cases). Strictly-speaking those URLs shouldn\u2019t even be equivalent, because foo/bar is a nonexistent path on both of those sites, so based purely on filesystem rules those should result in a 404 Not Found error. But things are being short-circuited for the sake of friendliness. And if you enter a URL manually, by copy-pasting e.g. https://beesbuzz.biz/foo/../code/ into your location bar, every modern browser I\u2019ve tried will just automagically coalesce the path component.\n\n(Note that how it coalesces // is inconsistent, in my experience; some browsers treat it as a subdirectory with an empty name, while others treat it as if it\u2019s the same as a single /, the same as UNIX.)\n\nBut it\u2019s not necessarily the case that the path will be coalesced. For example, here\u2019s a trivial WSGI application that just passes through a couple of things from the request:app.pydef app(environ, start_response):\n start_response(\"200 OK\", [(\"Content-Type\", \"text/plain\")])\n\n for key in ('HTTP_HOST', 'RAW_URI'):\n yield f'{key}: {environ[key]}\\n'.encode('utf-8')\nAnd here\u2019s some outputs when run through gunicorn; for starters, by default, curl coalesces /./ and /../ (but not //) client-side:bean:~ $ curl -i http://localhost:8000/foo//moo/./bar/../baz/\nHTTP/1.1 200 OK\nServer: gunicorn\nDate: Wed, 08 Apr 2026 20:36:44 GMT\nConnection: close\nTransfer-Encoding: chunked\nContent-Type: text/plain\n\nHTTP_HOST: localhost:8000\nRAW_URI: /foo//moo/baz/\nbean:~ $ curl -i http://localhost:8000/foo//moo/../../bar/\nHTTP/1.1 200 OK\nServer: gunicorn\nDate: Wed, 08 Apr 2026 20:42:56 GMT\nConnection: close\nTransfer-Encoding: chunked\nContent-Type: text/plain\n\nHTTP_HOST: localhost:8000\nRAW_URI: /foo/bar/\nBut a request that uses the path as-is will still at least pass through directly, at least through gunicorn itself:bean:~ $ curl -i http://localhost:8000/foo//moo/./bar/../baz/ --path-as-is\nHTTP/1.1 200 OK\nServer: gunicorn\nDate: Wed, 08 Apr 2026 20:40:09 GMT\nConnection: close\nTransfer-Encoding: chunked\nContent-Type: text/plain\n\nHTTP_HOST: localhost:8000\nRAW_URI: /foo//moo/./bar/../baz/\nBut in other testing I have found that, at least with a stack of nginx+gunicorn+Flask, the path coalescing takes place somewhere before it hits the actual application. (I do not have the patience to try to figure out where, exactly, not that it even matters.)\n\nAll this is to say, you cannot expect runs of multiple / or paths containing /./ or /../ to remain intact, even when the request is being made at the wire level, but you also cannot assume that the path will be pre-coalesced.Case-sensitivity/case-foldingCase-sensitivity and lack thereof in the hostname is also something you cannot rely on:$ curl -ivvv http://beesbuzz.biz/ | head\n* Host beesbuzz.biz:80 was resolved.\n[...]\n> GET / HTTP/1.1\n> Host: beesbuzz.biz\n[...]\n< link: <https://webmention.io/beesbuzz.biz/webmention>; rel=\"webmention\"\n< Link: <https://beesbuzz.biz/_tokens>; rel=\"token_endpoint\"\n[...]\n\n$ curl -sivvv http://BeesBuzz.Biz/ | head\n* Host BeesBuzz.Biz:80 was resolved.\n[...]\n> GET / HTTP/1.1\n> Host: BeesBuzz.Biz\n[...]\n< link: <https://webmention.io/beesbuzz.biz/webmention>; rel=\"webmention\"\n< Link: <https://beesbuzz.biz/_tokens>; rel=\"token_endpoint\"\n[...]\nIn this case, note that curl preserved the case of the domain name in the Host: parameter, but something within the stack converted the hostname to all-lowercase (as can be seen in the link headers in the response). Whether this is happening in nginx or Flask is uncertain (and I, again, do not feel a particular need to figure out where this takes place, although I\u2019d assume it\u2019s at the vhost \u2014 and therefore nginx \u2014 level), but gunicorn does preserve the case of the hostname (using the same minimal WSGI app as above):bean:~ $ curl http://LocalHost:8000/\nHTTP_HOST: LocalHost:8000\nRAW_URI: /\nSo, as with path coalescing, you cannot assume that elements will be case-folded for you, but you also cannot assume that they won\u2019t be.\n\nAnd of course, path resolution for resources is up to the underlying implementation; a webserver running on macOS or Windows will (usually) treat /foo.jpg and /foo.JPG as the same resource, while on Linux, those are different resources. Of course the browser will hopefully treat them as separate for the purpose of caching, but: you cannot guarantee this.\n\nAs one of my college professors once said, \u201cIf it makes a difference whether something is case-sensitive or not, you have made a mistake.\u201dhttp vs. https in generalNothing in the HTTP specification says that the same path on two different schemes will reflect the same resource; for example, http://example.com/ and https://example.com/ can very well be completely different websites. But I have seen plenty of browsers, web crawlers, and other software assume that they are the one and the same!\n\nAt its most trivial, this very site will have slightly different content for the two versions; there are a handful of places where out of necessity, some links do not appear on the http version, or where they are rendered as absolute links and will match the original request\u2019s scheme rather than directing to https.\n\nBut things can be a lot more complicated. For example, once upon a time I ran a site where the http version was an informational page and the https version was the webmail for the domain. It was silly to do it that way, and I stopped doing it when browsers started being \u201chelpful\u201d about automatically converting http URLs to https (not to mention when I stopped hosting my own email and switched to other hosting providers), but you absolutely cannot just assume that two pages will be the same despite different URL schemes.\n\n(Also, remember that URL schemes other than http and https exist! FTP, Gopher, and others might have fallen out of fashion, but they still exist. Not to mention nascent protocols like Gemini.)\n\nFrom a server implementation standpoint, you should assume that clients can and will treat differing schemes as identical, so if a website is available from both protocols, the content should match between them, and if something is only available via https, then an http request to the same resource should redirect to the https one.\n\nBut from a client standpoint, you really should consider the scheme to be a part of the URL.www. prefixes (and other subdomain issues)Back in the early days of the Internet, it was common for a domain to host a whole bunch of different services, for example ftp.example.com, irc.example.com, mail.example.com, and so on, and many of these would even be hosted by separate physical servers with their own IP addresses. So when the web started up as an experimental thing it was super common to just spin up another server named www, and that was the one and only way that people would reference the website; there often wouldn\u2019t even be a root domain A record.\n\nIn those days, the hostname used to resolve the site had no impact on the resource returned; in fact the Host: request header didn\u2019t even exist, and it wasn\u2019t until quite some time later that browsers started sending that, to support name-based virtual hosting. Every website needed its own IP address. (Note that many non-HTTP protocols still have this limitation.)\n\nAs the web became the primary use of the Internet, the www prefix convention remained, and you had a big hot mess of differing implementations:\nDedicated-IP hosts that have the root record and www resolve to the same server, which would then serve up the same content on either hostname\nSites that would map both example.com and www.example.com to the same virtual host configuration\nSites that would redirect www.example.com to example.com\nSites that would redirect example.com to www.example.com\nSites that serve up entirely different content for example.com vs. www.example.com\nHosts that only resolve from one or the other\nPretty much all of these remain to this very day, and to make things even more fun, many clients try to do \u201chelpful\u201d things where, for example, if example.com doesn\u2019t resolve it\u2019ll automatically redirect to www.example.com (or put up a prompt to that effect), or if a web crawler sees both hostnames it\u2019ll just assume that both are the same, or follow the preference of whomever implemented it.\n\nI don\u2019t even know what the best practice should be in this case. I guess it should be something like:\nClients should assume that www.example.com and example.com are different websites and use canonical URLs to sort out which is the \u201creal\u201d one if they both exist, even if this means potentially crawling the same site twice\nServers should redirect to the one that is correct\nThen again, the same issue comes up with sites that are available from multiple separate domains, and I\u2019ve also seen situations where badly-behaved crawlers will assume that all subdomains are equivalent (e.g. alice.example.com and bob.example.com), sometimes even getting confused by ccTLDs that are multi-level (like .uk) and thinking that, for example, example.co.uk and google.co.uk are the same site because they\u2019re both subdomains of co.uk! (This was especially bad back when so-called \u201cdynamic DNS\u201d providers were super common.)RedirectionsThere are so many different kinds of HTTP redirection, each with different implications on caching, HTTP method, and equivalence.\n\nClients should probably just note the type and target of a redirection rather than try to treat the URLs as equivalent; for example, /code and /code/ are distinct URLs and should be treated as such.\n\nLike, in theory, /code could not redirect and instead have entirely different content from /code/, but in practice, this will almost certainly cause Problems, and I\u2019m sure there\u2019s even crawlers out there which strip off trailing slashes and then expect the actual request to be redirected.In conclusionWhen implementing client software, you should do whatever you can to follow the specification, but when implementing server software, you should also be aware of common client implementation issues.\n\nIf you do run into an implementation issue, it is of course a kindness to inform the implementor of the mistake, but some of these issues are common enough that it\u2019s best to accommodate the common misunderstandings and just sigh quietly about it.\n\nI have of course reported this as a bug. They are, incidentally, otherwise amazing; use my referral link for 10% off your first year of service. \u21a9comments\n\n \n #HTML\n \n #conformance"
},
"name": "Code: Specification vs. implementation",
"post-type": "article",
"_id": "47891504",
"_source": "3782",
"_is_read": true
}